

跟大家伙儿聊聊咱这 Hadoop 的那点事儿。这 Hadoop ,可是个处理大数据的能手,它有三个核心组件,就像是三驾马车,拉着大数据这辆车跑得飞快。那这三驾马车都是谁?别急,听我慢慢道来。
咱得准备好环境。我,就在我的电脑上折腾,装个虚拟机,在里面搞三个节点,一个主节点,两个从节点,这就算是把 Hadoop 的集群环境给搭起来。搭环境这事儿,说难也不难,就是得细心,一步一步来,按照网上的教程,基本上都能搞定。
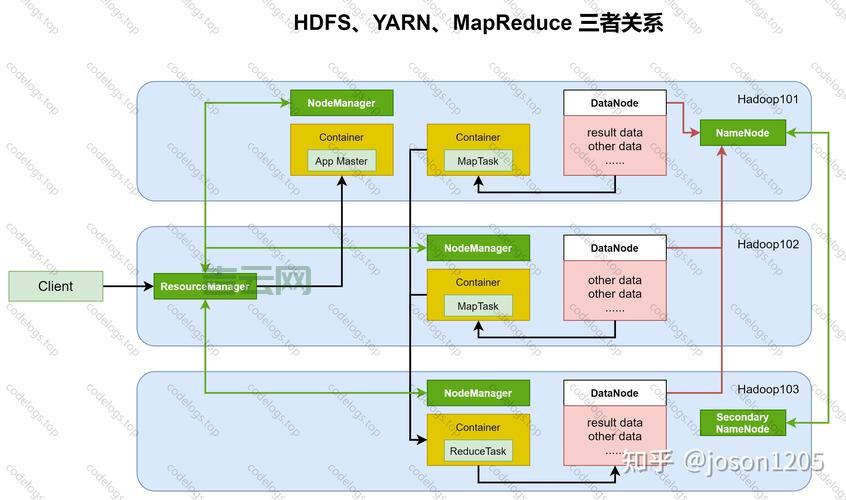
环境搭好,咱就来看看这三驾马车。第一驾,叫做 HDFS,全称是 Hadoop 分布式文件系统。这玩意儿,说白,就是能把一大堆数据,分散存储到不同的机器上,这样一来,数据多也不怕,咱有的是地方放。我,就在主节点上,启动 HDFS,然后用命令看看,还真能看到那些数据文件,都乖乖地躺在那儿。这就是分布式文件系统的好处,高容错性,数据不容易丢,还能快速访问。
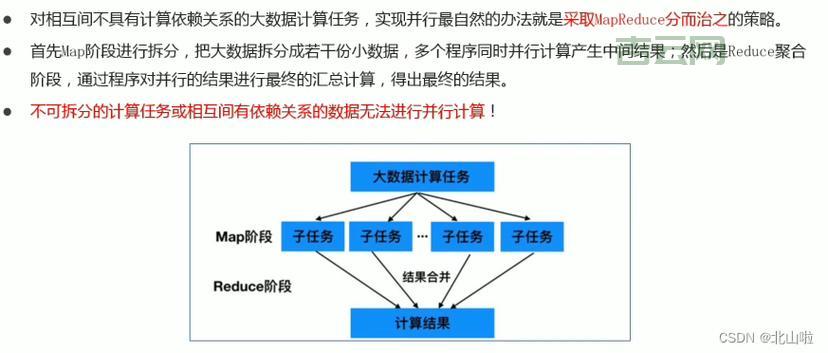
第二驾马车,叫做 MapReduce,这是个计算框架。有 HDFS,数据是存好,可咱不能光存不用,还得拿来分析分析,算一算,对?MapReduce 就是干这个的。我就写个简单的程序,让它去统计一个文本文件中每个单词出现的次数。这程序,分两步走,第一步叫 Map,就是把数据拆成一小块一小块的,第二步叫 Reduce,就是把结果汇总起来。我把程序打包,扔到 Hadoop 集群上运行,没一会儿,结果就出来,还挺快。
一驾马车,叫做 YARN,这是个资源管理器。啥叫资源管理器?就是说,这 Hadoop 集群里,有很多机器,每台机器都有自己的 CPU、内存啥的,YARN 就负责把这些资源管起来,谁需要,就分配给谁。比如说,我要跑 MapReduce 程序,YARN 就得给我找几台机器,把程序分配下去,让它们一起干活。我就试试,提交一个任务,YARN 很快就给安排上,任务在各个节点上跑得欢着。
这三大组件,HDFS 负责存数据,MapReduce 负责算数据,YARN 负责管资源,三者一配合,那真是天衣无缝,大数据处理起来,杠杠的。这 Hadoop 的学问大着,我也还在学习中,今天就先跟大家分享这么多,以后有啥新发现,再来跟大家唠唠。
经过这么一折腾,我对 Hadoop 的这三个核心组件算是有个初步的认识。这玩意儿,确实挺强大的,能处理海量数据,而且还挺稳定的。以后,我得多琢磨琢磨,看看能不能用它来解决一些实际问题。对,你们要是也有啥想解的,或者有啥好的实践经验,也欢迎来跟我交流交流,咱一起学习,一起进步!
实践总结
- 搭建 Hadoop 集群环境是第一步,这一步需要细心操作,确保每个节点都能正常通信。
- HDFS 分布式文件系统能够实现数据的分布式存储,提高数据的可靠性和访问速度。
- MapReduce 计算框架可以将大任务分解成小任务,并行处理,大大提高计算效率。
- YARN 资源管理器负责集群资源的分配和管理,使得任务可以高效地在集群中运行。
好,今天就啰嗦这么多。看看天儿也不早,我也该歇息去。大家伙儿也早点休息,养足精神,明天继续搞事情!
