

今天跟大家唠唠我昨天刚折腾的PERL 的 `chomp` 函数,这玩意儿,说起来简单,但真用起来,有时候还挺容易掉坑里的。
事情是这样的,我最近在写一个 PERL 脚本,需要处理一些文本文件。这些文件里的每一行末尾都有个讨厌的换行符 `\n`。我寻思着,这玩意儿得去掉,不然处理起来太麻烦。
我直接就用 `chomp`。心想,这还不简单?`chomp` 一下,万事大吉。
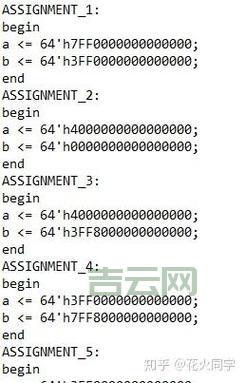
perl
#!/usr/bin/perl
use strict;
use warnings;
my $text = "Hello, world!\n";
print "原始字符串: '$text'\n";

chomp($text);
print "chomp 后的字符串: '$text'\n";
跑一下,没毛病,换行符没。
但是,好景不长,问题来。我开始处理真实的文件,发现有些行的末尾,竟然没有换行符!这下 `chomp` 就尴尬,它啥也不干,直接跳过去。
我当时就懵,这可咋办?总不能先判断一下有没有换行符再 `chomp` ?那也太傻。

然后我就去网上搜一下,发现原来 `chomp` 的一个特性:它只移除字符串末尾的换行符,如果末尾没有,它就什么也不做。
明白这一点,我就放心。至少我知道 `chomp` 不会把我的字符串给搞坏。
我就开始想,有没有更好的办法来处理这个问题。我想到正则表达式。
perl
#!/usr/bin/perl
use strict;

use warnings;
my $text = "Hello, world!\n";
print "原始字符串: '$text'\n";
$text =~ s/\n$//;
print "替换后的字符串: '$text'\n";

用 `s/\n$//` 替换掉末尾的换行符。这样,不管有没有换行符,都能保证处理后的字符串是干净的。
但是,我又遇到新的问题。有些文件是 Windows 格式的,换行符是 `\r\n`。我的正则表达式只能处理 `\n`,处理不 `\r\n`。
这可咋办?难道要写两个正则表达式?这也太麻烦。
后来我想到一个更好的办法,就是先统一换行符,再进行处理。
perl
#!/usr/bin/perl

use strict;
use warnings;
my $text = "Hello, world!\r\n";
print "原始字符串: '$text'\n";
$text =~ s/\r\n/\n/; # 将 \r\n 替换为 \n
chomp($text);
print "chomp 后的字符串: '$text'\n";
先把所有的 `\r\n` 替换成 `\n`,然后再 `chomp`。这样,不管是什么格式的文件,都能正确处理。
我把这个方法应用到我的脚本中,果然,一切都顺利多。
`chomp` 虽然简单,但是也要注意它的特性。在处理文本文件时,最好先统一换行符,再进行处理,这样可以避免很多不必要的麻烦。