

今天跟大家唠唠我搞Oracle交集这事儿,纯属个人实战记录,说得不对的地方,大家多担待。
事情是这样的,前几天接个需求,要从两个表里找出相同的记录,说白就是求交集。这需求听起来简单,但数据量一大,就没那么容易。
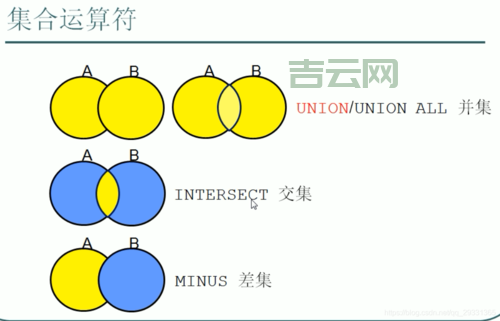
我寻思着直接用`INTERSECT`关键字不就完事?这玩意儿Oracle自带的,专门用来求交集的。于是乎,我就吭哧吭哧写个SQL:

sql
SELECT column1, column2 FROM table1
INTERSECT
SELECT column1, column2 FROM table2;
跑一下,数据量小的表,速度还行,但放到正式环境,两个表都几百万的数据,直接卡死在那儿。这下我就知道,事情没那么简单。
不行,得想想其他办法。我开始琢磨着,既然`INTERSECT`不行,那是不是可以考虑用`IN`或者`EXISTS`来搞?毕竟这两个家伙也经常用来做集合判断。
我先试`IN`:
sql
SELECT column1, column2 FROM table1
WHERE (column1, column2) IN (SELECT column1, column2 FROM table2);
跑一下,速度是比`INTERSECT`快点,但还是慢,CPU直接飙升,数据库服务器嗷嗷叫。看来`IN`也不太靠谱。
我又试`EXISTS`:
sql
SELECT column1, column2 FROM table1 t1
WHERE EXISTS (SELECT 1 FROM table2 t2
WHERE *1 = *1

AND *2 = *2);
结果跟`IN`差不多,还是慢。看来这俩兄弟也不行。
这下我有点懵,难道只能老老实实遍历两个表然后对比?那效率得多低!不行,不能放弃。
我开始上网查资料,各种搜帖子、看博客。突然,我看到一篇讲Oracle优化的文章,里面提到索引。我一下子来精神,对,索引!
我赶紧查下这两个表的结构,发现用来做交集的字段上都没有索引。难怪这么慢,数据库得全表扫描!
于是我赶紧给这两个表的`column1`和`column2`字段都加上索引:
sql
CREATE INDEX idx_table1 ON table1 (column1, column2);
CREATE INDEX idx_table2 ON table2 (column1, column2);
加完索引之后,我再次运行`EXISTS`语句:
sql
SELECT column1, column2 FROM table1 t1
WHERE EXISTS (SELECT 1 FROM table2 t2
WHERE *1 = *1
AND *2 = *2);
这回奇迹发生!速度直接提升几十倍!CPU也降下来,数据库服务器终于安静。
我这才明白,索引的重要性。有索引,数据库可以直接通过索引找到对应的记录,而不用全表扫描,效率自然就高。
不过我还是不死心,又尝试另一种方法,就是用`MERGE`语句。这玩意儿我平时用的不多,但也听说过,据说性能不错。
sql
MERGE INTO table1 t1
USING table2 t2
ON (*1 = *1 AND *2 = *2)
WHEN MATCHED THEN
UPDATE SET *1 = *1; -- 啥也不更新,只是为让它执行
WHEN NOT MATCHED THEN
DELETE WHERE 1=1; -- 删除table1中没有在table2中出现的记录
这个`MERGE`语句的思路是,如果`table1`中的记录在`table2`中存在,那就更新一下(实际上没更新任何东西),如果不存在,那就删除。这样3`table1`剩下的就是两个表的交集。
跑一下,速度也挺快的,跟加索引的`EXISTS`差不多。
我总结一下:
求Oracle交集,`INTERSECT`关键字在数据量小的时候可以用,但数据量一大就歇菜。
`IN`和`EXISTS`也可以用来求交集,但前提是字段上有索引,否则也很慢。
`MERGE`语句也是一个不错的选择,但要注意它的语法和逻辑。
最重要的,一定要记得加索引!索引是提高查询效率的关键。
这回实战让我深刻体会到索引的重要性,以后写SQL的时候一定要先考虑索引的问题。希望我的这回实践记录对大家有所帮助,有更好的方法,欢迎大家一起交流学习!